

-
作者: lin.sinchen
查看: 3223
回復: 0
 收藏
收藏 分享
分享 分享
分享+ MORE精選文章:




相關帖子
晶片製造速度起飛!台積電、新思科技 ...
GTC 2024大會上,NVIDA正式宣布,為加快下一代先進半導體晶片...
NVIDIA 推出巨大的超級晶片 Blackwel ...
NVIDIA 宣布 NVIDIA Blackwell 平台已經到來,為運算新時代提...
Nvidia 發誓今年將推出 Blackwell GP ...
看來今年Nvidia將專注於H200而不是B200。 當 Nvidia 稍早推出首...
- 解碼 AI 最新的開發者工具和應用程式 ...
- NVIDIA 生成式人工智慧研究 LATTE3D ...
- 啟動引擎:NVIDIA 和 Google Cloud ...
- 傳播產業的突破:NVIDIA Holoscan fo ...
- Ampere 世代新卡 NVIDIA RTX A400 和 ...
- 全面開放 NVIDIA GPU 加速 Meta Llam ...
- 傳聞 RTX4060Ti 下半月供應緊缺,NVI ...
+ MORE活動推薦:

Uniface RGB機殼 玩家體驗分享活動
性能即是一切 與 Uniface RGB 中塔機箱探索效益和性能的完美平衡, ...

T5 EVO 移動固態硬碟 玩家體驗分享活動
自信無懼 生活帶著你遨遊四方。高性能的 T5 EVO 在工作、創作、學習 ...

ZOTAC 40 SUPER顯示卡 玩家開箱體驗活動 --
頭獎 dwi0342 https://www.xfastest.com/thread-286366-1-1.html ...

FSP VITA GM 玩家開箱體驗分享活動
[*]符合最新 Intel ® ATX 3.1電源設計規範 [*]遵從 ATX 3.1 推薦 ...
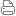


[業界新聞] NVIDIA Hopper 在 MLPerf 的生成式人工智慧領域取得飛躍性進展 |

| |
|
|
|



 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 顯身卡
顯身卡
- 特別活動
- Computex報導
- GAMFORCE
