

-
作者: lin.sinchen
查看: 6286
回復: 0
 收藏
收藏 分享
分享 分享
分享+ MORE精選文章:



相關帖子
感恩之行!NVIDIA 與 SEGA 歡慶 30 ...
骨灰級的遊戲主機玩家肯定對 NVIDIA 與 SEGA 並不陌生,從早期 N...
日本企業與新創以 NVIDIA Nemotron ...
NVIDIA 提到日本領先企業、新創公司與研究機構正運用 NVIDIA N...
NVIDIA 推出 Jetson Thor 新系列 T30 ...
近期 NVIDIA 宣布,推出全新 Jetson Thor 系列產品,包括 T3000 ...
- WireView Pro 轉接器在 RTX 5090 顯 ...
- NVIDIA 發佈 CUDA Toolkit 13.4 開發 ...
- AI 代理將創意工具帶給數百萬使用者 ...
- NVIDIA Vera Rubin 推升每瓦效能,為 ...
- AMD攜手Anthropic部署2GW AI運算平台 ...
+ MORE活動推薦:

GO27Q24G Gaming Monitor 玩家開箱體驗分享
WOLED優勢: [*]四邊無邊框設計 [*]解鎖OLED亮度新境界 Micro Lens ...

Micron Crucial T710 SSD 玩家開箱體驗分享
進入疾速前進! 快速邁向終局勝利 使用 Crucial® T710 Gen5 NVMe® ...

COUGAR ULTIMUS PRO玩家開箱體驗分享活動
ULTIMUS PRO 終極功能,無限連接 Ultimus Pro 採用簡潔的 98% 鍵盤佈 ...

COUGAR AIRFACE 180 玩家開箱體驗分享活動
AIRFACE 180 180mm 風扇,威力加倍 Airface 180 預裝兩顆 180mm PWM ...


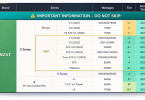
[業界新聞] NVIDIA 加速 Gemma 4 在 RTX PC 與 DGX Spark 的地端部署推進代理 AI 應用 |

| |
|
|
|



 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 顯身卡
顯身卡
- 特別活動
- Computex報導
- GAMFORCE
