

-
作者: lin.sinchen
查看: 11441
回復: 0
 收藏
收藏 分享
分享 分享
分享+ MORE精選文章:




相關帖子
A 卡大 VRAM!ASUS TURBO Radeon AI ...
隨著 AI 模型日漸茁壯,不僅提升模型的參數量更提升複雜度,而...
搭載 Arm 架構的 NVIDIA RTX Spark ...
數十年來,個人電腦的設計思維一直以人們使用應用程式為核心場...
Intel x86 CPU 搭上 NVIDIA RTX GPU ...
來自 Erdi Özüağ 的 X 爆料,以 Intel x86 CPU 搭配 NVIDIA...
- A 卡大 VRAM!ASUS TURBO Radeon AI ...
- NVIDIA 於 Unreal Fest 發布 PUBG Al ...
- NVIDIA 發布 RTX Remix 1.5 更新:導 ...
- 加大 VRAM!NVIDIA RTX PRO™ 5000 7 ...
- 加大 VRAM!NVIDIA RTX PRO™ 5000 7 ...
+ MORE活動推薦:

Micron Crucial T710 SSD 玩家開箱體驗分享
進入疾速前進! 快速邁向終局勝利 使用 Crucial® T710 Gen5 NVMe® ...

COUGAR ULTIMUS PRO玩家開箱體驗分享活動
ULTIMUS PRO 終極功能,無限連接 Ultimus Pro 採用簡潔的 98% 鍵盤佈 ...

COUGAR AIRFACE 180 玩家開箱體驗分享活動
AIRFACE 180 180mm 風扇,威力加倍 Airface 180 預裝兩顆 180mm PWM ...

COUGAR GR 750/GR 850 玩家開箱體驗分享活
ATX 3.1 兼容,穩定供電無憂 COUGAR GR 系列通過 80 PLUS 金牌認證 ...
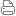


[業界新聞] NVIDIA 發表全新 Ampere 架構 A100 GPU 與 DGX A100 打破 5 Petaflops AI 效能和 EGX Edge 平台 |

| |
|
|
|



 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 喧囂卡
喧囂卡 變色卡
變色卡 顯身卡
顯身卡
- 特別活動
- Computex報導
- GAMFORCE
